
I truly think, I just fell in love with a program. I’m talking about Scrivener. Since I’m doing research / academic writing rather than novel writing, I had not really looked at the program after I had bought it and played a bit with it a couple of years ago. Now, I’m starting here a series of blog articles about how to make Scrivener really work for academic writing and research. It’ll go very much in detail.
Motivation
First of all, here’s my motivation: I used the obvious combination of Sublime Text, BibDesk and LaTeX, for writing about 120 papers during my MBA. I even published, at some point, my template to GitHub. Don’t really download it, as I’ve changed it over the last year, and I am now substantially redoing it.
But anyway, that template allowed me to have a standard layout and template for all my papers – every week I would clone it, write whatever was there to write, run through the Makefile that’s embedded there, and done.
Yet, the more I think about that, having an approach where I have essentially my layout of a fixed set of chapters, works conceptually only if you mostly already know what structure you are going to follow. LaTeX is very good, of course, at re-arranging stuff and keeping all your references intact, but then you’d still reshuffle content between chapters.
That works well for an MBA, where people will tell you, read those articles, write something about that question about them. I mean, I honestly believe that the pure visual excellence of my papers was a big part in my becoming Student of the Year at Liverpool university…
“Your paper makes no goddamn sense, but it’s the most beautiful thing I have ever laid eyes on.” Source: Internet (Peer reviewed, trust-worthy).
Now, what changes when you go from MBA, paper writing mode, to DBA/PhD, research mode? Essentially, from a research standpoint, you probably have no idea what to read, so you’re doing an actual literature research. You have bits and pieces of information flying around.
In other words, you don’t have your couple of chapters that you know in advance. You’ve fragments that you re-arrange all the time.
Enter Scrivener
Now, Scrivener very much can be seen as a management interface for text snippets. So rather than having chapters, you may have bits and pieces of information:
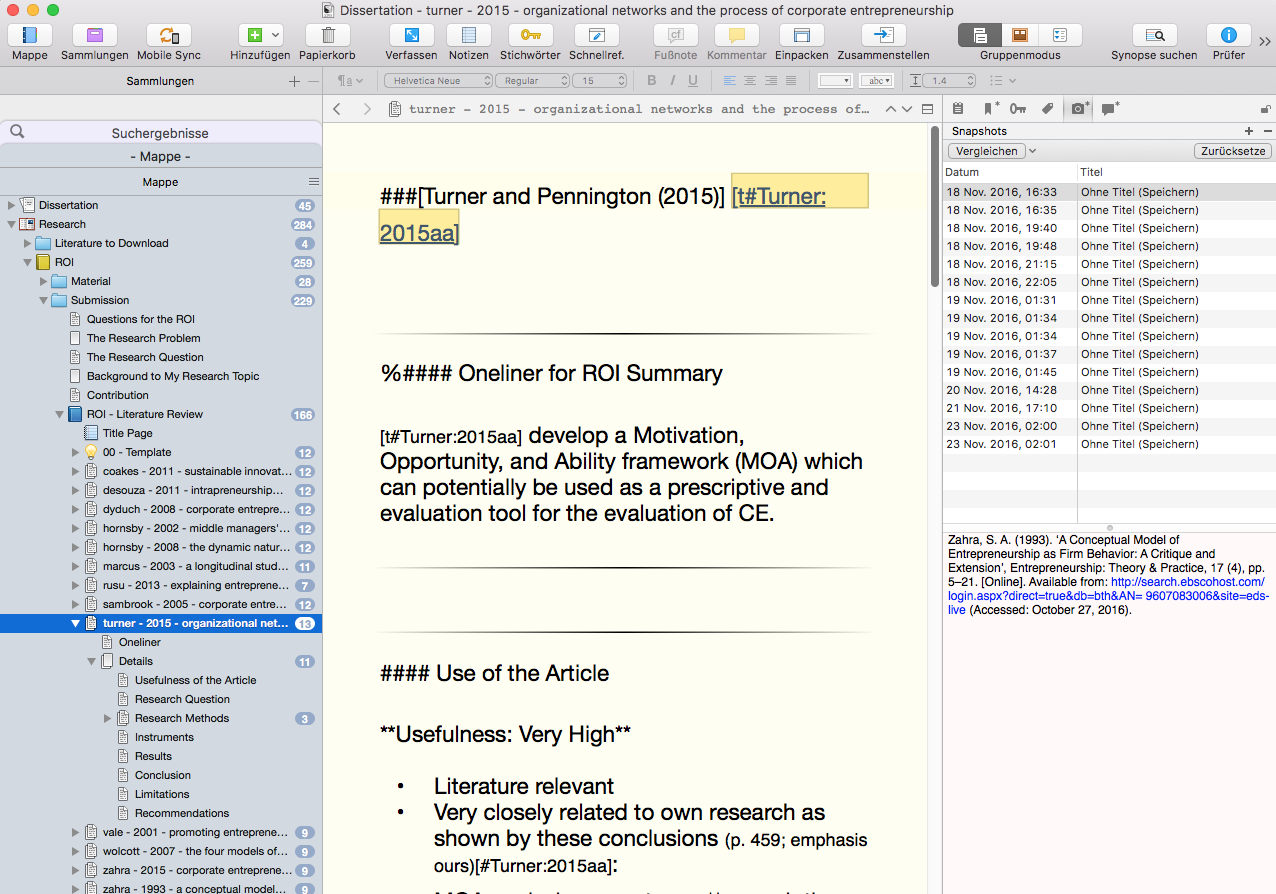
Scrivener – Bits and Pieces all over the Place
Forget about these funny ### for the moment. I’m going to write a different post on that. I’ve written TeXDown over the last couple of days, and if you don’t want to test it right now, then wait for the blog post that I’m going to write about it soon. But besides parsing out ### and replacing it with something that LaTeX understands (like, \section{…}\label{…}), what I found myself very quickly developing TeXDown into was much more than a parser for that markup (actually, MarkDown) code.
Because, in order to parse the content that was in Scrivener, I needed to parse the Scrivener data structures, and also its directory hierarchy.
Scrivener Data Structure
So here’s what I’ve learned in the meanwhile. And I don’t claim I understand everything (for sure, I can only speak about Scrivener on a Mac), but here’s what essentially happens: A “Scrivener” file, let’s name it “Dissertation”, is actually a directory “Dissertation.scriv”, with a whole lot of files in it.
Let’s look at the details:
- Every single node in the above mentioned screenshot of Scrivener, if it has some text in it, will have a corresponding file on the disk, in a subdirectory Files/Docs.
- Every single node has a unique, numerical, ID, let’s say, 123.
- The file in Files/Docs is named, then, 123.rtf.
- At the top level of the Dissertation.scriv directory, there’s one XML file, named Dissertation.scrivx. That file contains the mappings between the content that you see, i.e., your hierarchical structure, and the actual files on disk.
- There are also some more files related to 123, so for example,
- Snapshots/123/*.rtf which timestamps as filenames (see screenshot above), as well as each one file Snapshots/123/index.xml that contains the mappings of snapshot files to names of snapshots that you can potentially give.
- Likewise, there’s things like Files/Docs/123.comments, which exists when you use footnotes or comments in scrivener on your document fragment, and these files are xml files that contain, for each footnote, an rtf code in a CDATA field; the 123.rtf, then, contains a hyperlink with a unique ID for each comment.
- Ultimately, if you also have written something on the front card (synopsis) of an asset in Scrivener, you’d have e.g., a file Files/Docs/123_synopsis.txt.
- You can, in your Scrivener frontend, actually have conflicting names of assets: It is no problem to do something like a folder /x, and having two assets y in it, with different content. That works, because essentially, the file content is mapped via indirection by the .scrivx file to what you see.
Enter Git
Git is of course the most awesome versioning tool on the planet. Now how can we make it work with Scrivener? If we just throw something at Git – like, the Scrivener directory, and – by virtue of .gitignore, exclude the stuff that changes too frequently, and is too irrelevant for us…
*/Files/binder.autosave */Files/binder.backup */Files/search.indexes */Files/user.lock */Files/Docs/docs.checksum */QuickLook/ */Settings/ui.plist
we can do this in the directory where we have our Scrivener “file” (like, where we have Scrivener.scriv):
rm -rf .git git init git add . git commit -a -m "Initial version"
This will create a new Git repository locally for us, add everything, and then commit it. Once we’ve done that, let’s fire up the most awesome Git front end on the planet, Tower (it costs about 80 bucks, but really, do get it…), and put our content into a branch A:
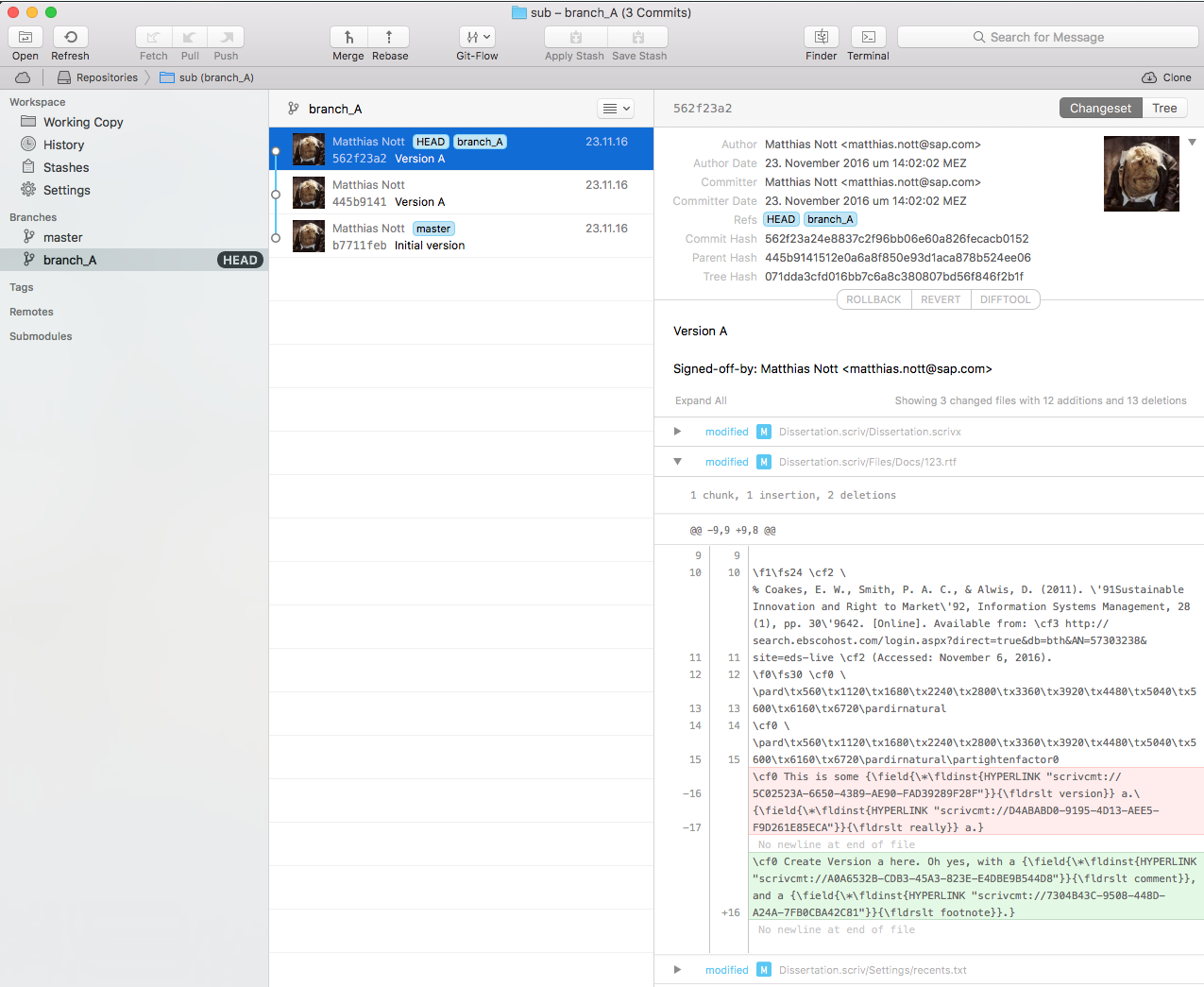
Scrivener seen from Tower
So on the right side, you can see the effect of the fact that from a file system point of view, you have only “numbers” for asset names, and also you have them all on the same directory level.
And, you can see that in the preview, you see some text, but you also see a whole lot of rtf markup, because, well those are rtf files after all.
While Git has no problem with either – rtf files are text files – from a usability standpoint, both issues are not quite easy to solve. Let’s look at an effect of it.
Let’s edit the file in Scrivener, change something, like add some text and a footnote:
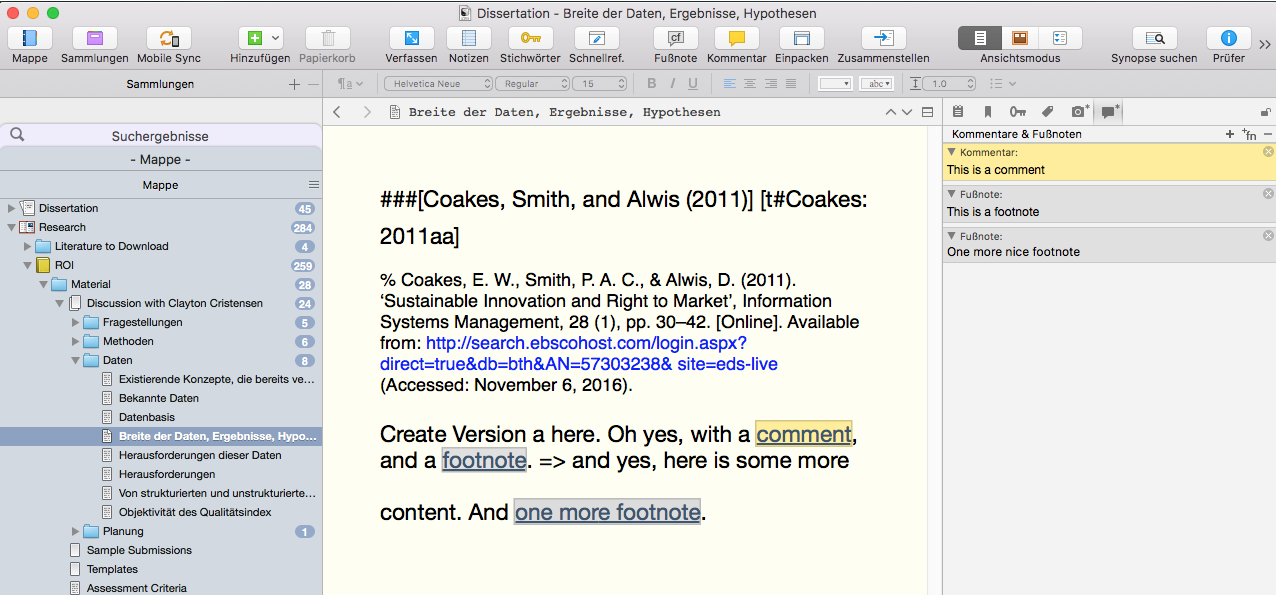
Using Scrivener to amend some file
Here is what Tower now sees, when we close Scrivener, and look at Tower:
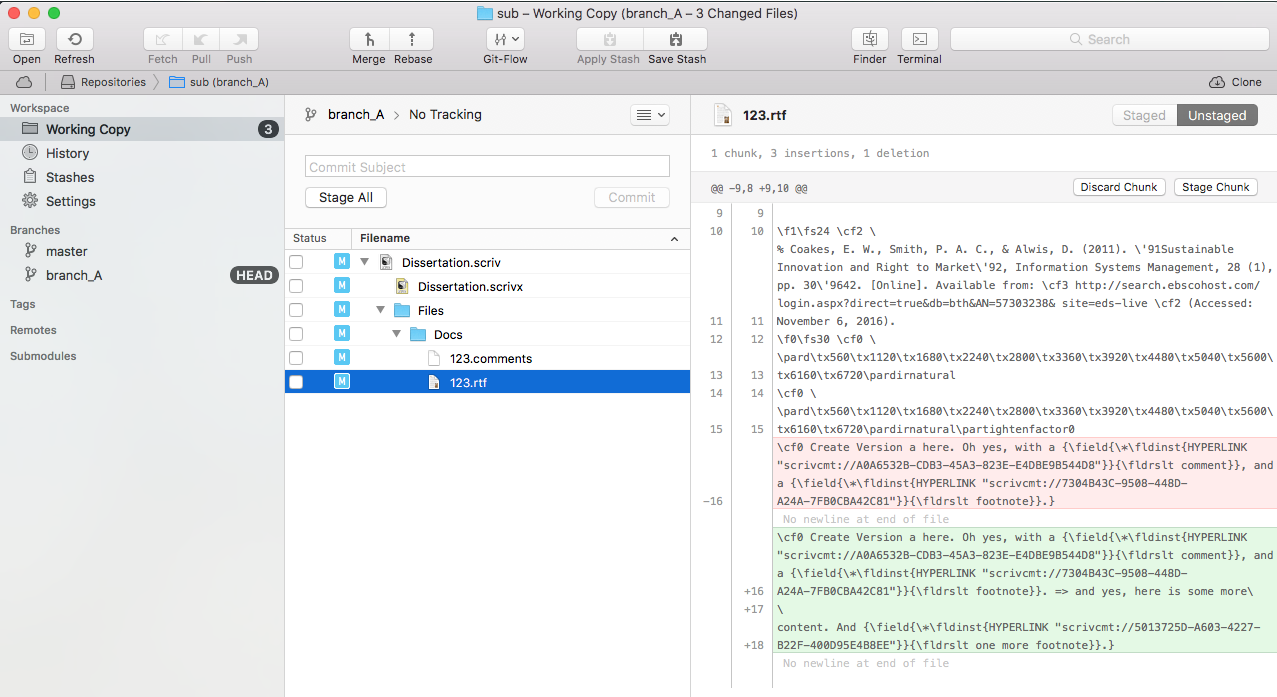
How Tower sees differences in Scrivener files
On the right side, in green, you see the changes that Tower has seen, vs. the previous content, which is shown in red. Now, if link Tower up with the most awesome diff tool on the face of this earth, Kaleidoscope (it costs another 70 bucks, but really, do get it…), we can compare both versions and see the changes in a much clearer way:
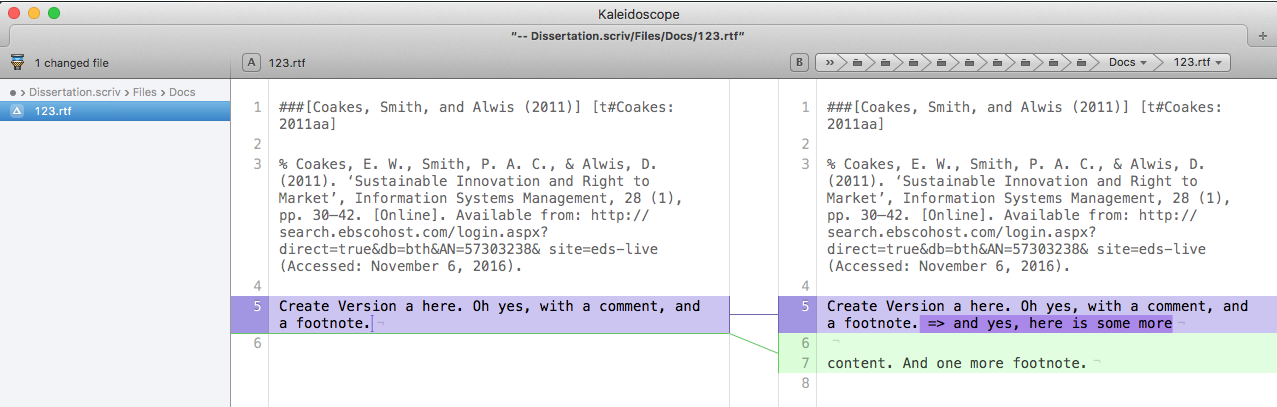
Kaleidoscope is good at comparing RTF…
Kaleidoscope doesn’t show us images, should we have embedded them in an rtf – which I can live with, since I would probably not integrate an image into the rtf at this point – I’d rather use the LaTeX way of linking to the image on disk. But maybe I’m going to change that – after all, I could use Scrivener for that too, and when running TeXDown, I could extract those files, put them into a directory for LaTeX, then add around the place where they were a template for images that I anyway use all over the place, and then this way have a much easier way of adding images to my stuff. I don’t have so many images anyway, but that might be an option. And since tables suck both with MultiMarkDown – and hence I was of course to lazy to even put anything about tables into TeXDown – as well as with LaTeX, I could just create the tables some other place, put them into PDF, and then use the mentioned approach to have Scrivener have a placeholder for me, also have the PDF, and then have TeXDown take care of all the rest. But I’m digressing…
Anyway, let’s create the current version into a branch b. Then merge b back into a, which will of course create a nice merge conflict.
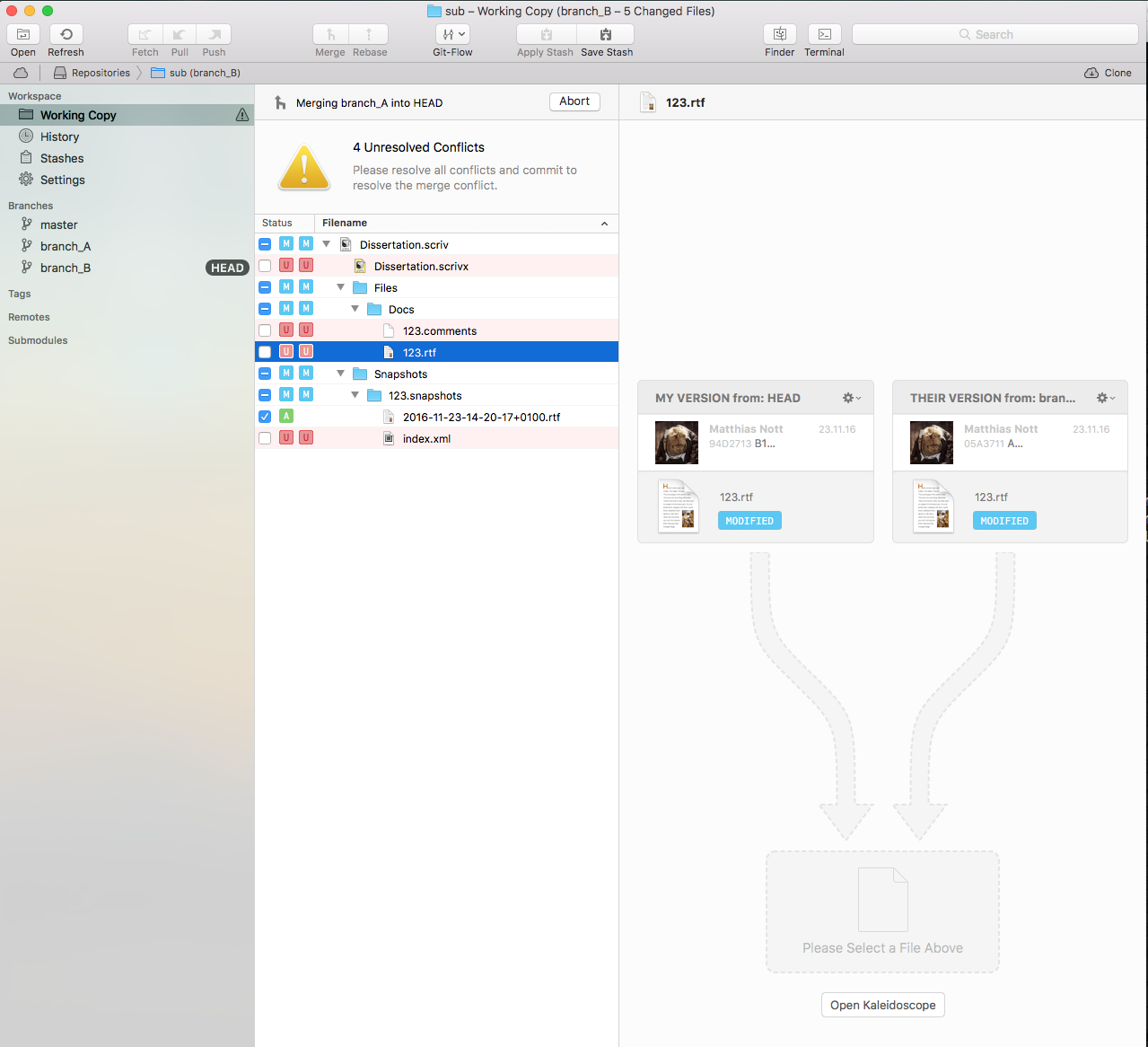
Tower sees a merge conflict
Which we then can look at in Kaleidoscope:
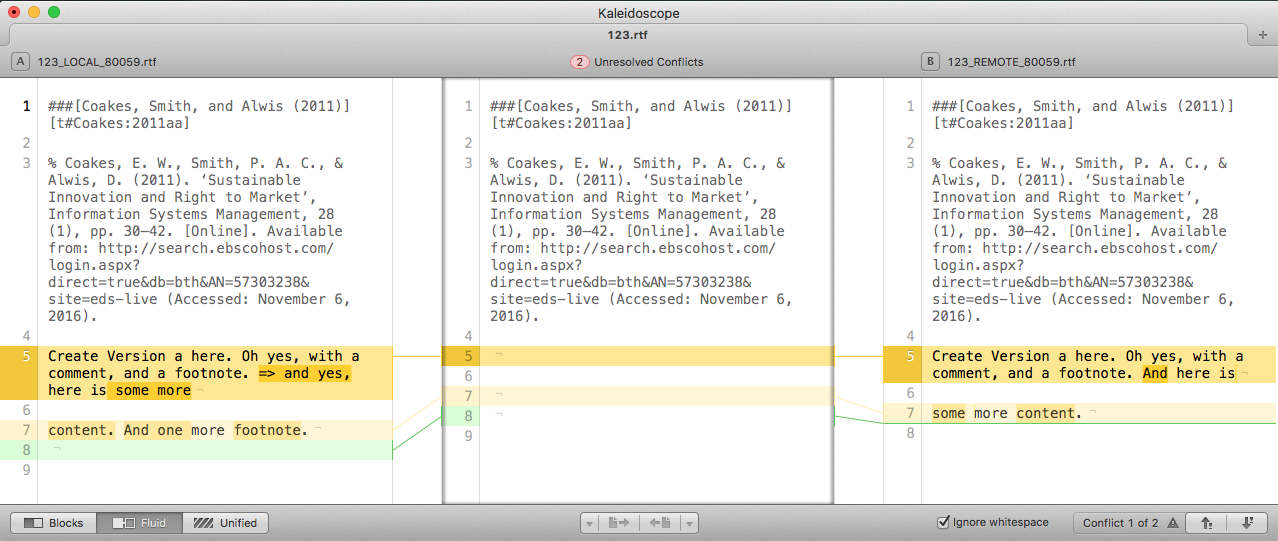
…but Kaleidoscope cannot merge RTF
Notice those buttons in the status bar, right in the middle? If it was a text file, those would not be greyed out, but you could choose, for each merge conflict, whatever side you prefer, into the merged content in the middle.
Just, it doesn’t work with rtf, which leaves us with two problems:
- How can we make better sense of those 123.rtf filenames, all living in one directory, seen from the point of view of the file system / Git / Tower?
- How can we actually make Kaleidoscope able to merge the content?
Possible Solutions
File System Level
What we’ve seen so far, is that the file system level operations against a Scrivener project are possible, but also not very intuitive – even for an avid file system / shell user, simply because you’ll have to link whatever 123.rtf is to whatever you’ll see in Scrivener.
My little tool TeXDown, that I had linked to above, can help us here: It actually allows you to get that mapping:
$ texdown.pl Dissertation -l -p / | grep 123 [ 123] /Research/ROI/Material/Discussion with Clayton Christensen/Daten/Breite der Daten, Ergebnisse, Hypothesen
But then, we’d logically want to re-create the hierarchy that you have in Scrivener, on the file system. Hence, we would have to expect the users to not do either of two things:
- Have naming conflicts on a given hierarchy level
- Have characters in the object names that won’t work on the file system (like, a slash)
Both we could of course deal with, but then we’d have to somehow be clever about the mapping. For example, we could remove all those incompatible characters, replace them by spaces, and also add the “123”, i.e., the object ID, to the file / directory name. We could then both ways export and import the files using some little script.
Summary: File system level: can be solved. We would create a folder hierarchy that is disjunct from that Scrivener works on, and which we can then work on with Git. Essentially, the workflow would be like this:
- Exit Scrivener
- Run script to dump Scrivener content into a file system hierarchy
- Have Git look at that content
- Do something, like branching, merging
- Run script to re-import Scrivener into Scrivener’s directory
- Start Scrivener
This can clearly work, except for the fourth point. Let’s look at that.
File Level
Yes we can export Scrivener stuff into our own hierarchy. But what can we then see? As we saw before, visually, we would now not see like 123.rtf all in one directory, we would see some actual names – but still:
- The file content would appear mostly garbled
- We can diff it, but not merge it
So to solve that, there are several options, and neither is perfect in anyway. All of them come at some cost. All of them involve converting rtf into plain text, and back – which by definition comes with a loss.
Convert RTF to Plain Text
MacOS comes with a nifty tool called Textutil, which is able to convert RTF into plain text:
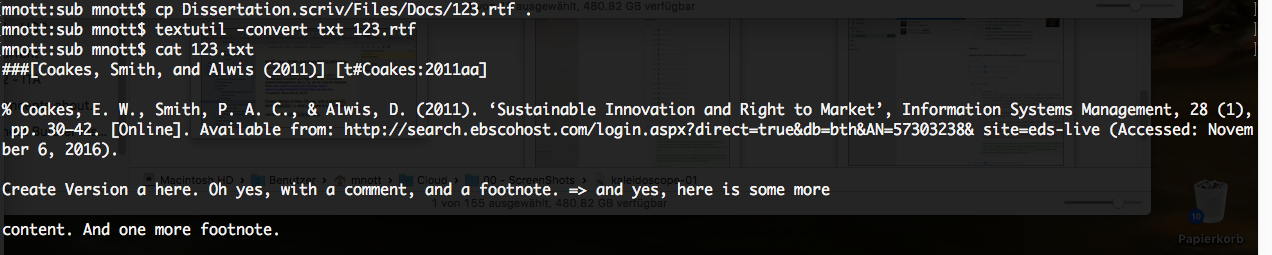
Using Textutil to convert RTF to TXT
As you can see, that basically works, but it of course looses all other information – like, our footnotes. And really, there’s just also other ways to convert RTF to TXT, like Gnu’s unrtf, or like this little snippet of Perl:
#!/usr/bin/perl # <= Adapt if needed
###################################################
#
# rtf2txt.pl
#
# Convert a RTF ot Plain Text
#
###################################################
# (c) Matthias Nott, SAP. Licensed under WTFPL.
###################################################
use strict;
use warnings;
binmode STDOUT, ":utf8";
use utf8;
use RTF::TEXT::Converter;
print rtf2txt($ARGV[0])."\n";
#
# rtf2txt
#
# Convert a file from rtf to a txt string.
#
# $file : The file to convert
#
sub rtf2txt {
my $file = shift;
my $result;
my $self = new RTF::TEXT::Converter(output => \$result);
$self->parse_stream($file);
return $result;
}
I know, it is not nice, but now let’s throw some rtf at it:
$ rtf2txt.pl 123.rtf HelveticaNeue;###[Coakes, Smith, and Alwis (2011)] [t#Coakes:2011aa] % Coakes, E. W., Smith, P. A. C., & Alwis, D. (2011). `Sustainable Innovation and Right to Market', Information Systems Management, 28 (1), pp. 30-42. [Online]. Available from: http://search.ebscohost.com/login.aspx?direct=true&db=bth&AN=57303238& site=eds-live (Accessed: November 6, 2016). Create Version a here. Oh yes, with a comment, and a footnote. => and yes, here is some more content. And one more footnote.
See that second line? For some reason that sometimes happens. Just running it again may, or not, show that HelveticaNeue;…
$ rtf2txt.pl 123.rtf ###[Coakes, Smith, and Alwis (2011)] [t#Coakes:2011aa]
This seems to be some problem with the RTF::TEXT::Converter module. I’ve seen that with other people’s code, too.
Anyway, we could still live with that, but do we want to live with losing our footnotes? I guess not. Well then, we can also use Textutil to convert into HTML rather than into plain text:
$ textutil -convert html 123.rtf $ cat 123.html###[Coakes, Smith, and Alwis (2011)] [t#Coakes:2011aa]
% Coakes, E. W., Smith, P. A. C., & Alwis, D. (2011). ‘Sustainable Innovation and Right to Market’, Information Systems Management, 28 (1), pp. 30–42. [Online]. Available from: http://search.ebscohost.com/login.aspx?direct=true&db=bth&AN=57303238& site=eds-live (Accessed: November 6, 2016).
Create Version a here. Oh yes, with a comment, and a footnote. => and yes, here is some more
content. And one more footnote.
As you can see, it does maintain our footnotes, and I’ve tested that we can convert back and forth between html and rtf, and it will still work with Scrivener (always provided Scrivener is closed during external file manipulations).
But then again, this replaces one hard to read format (rtf) by another hard to read format (html) – it adds so much more stuff to the file that the actual textual content is even harder to see. It allows us to formally merge, with Kaleidoscope, but watch how that now looks:
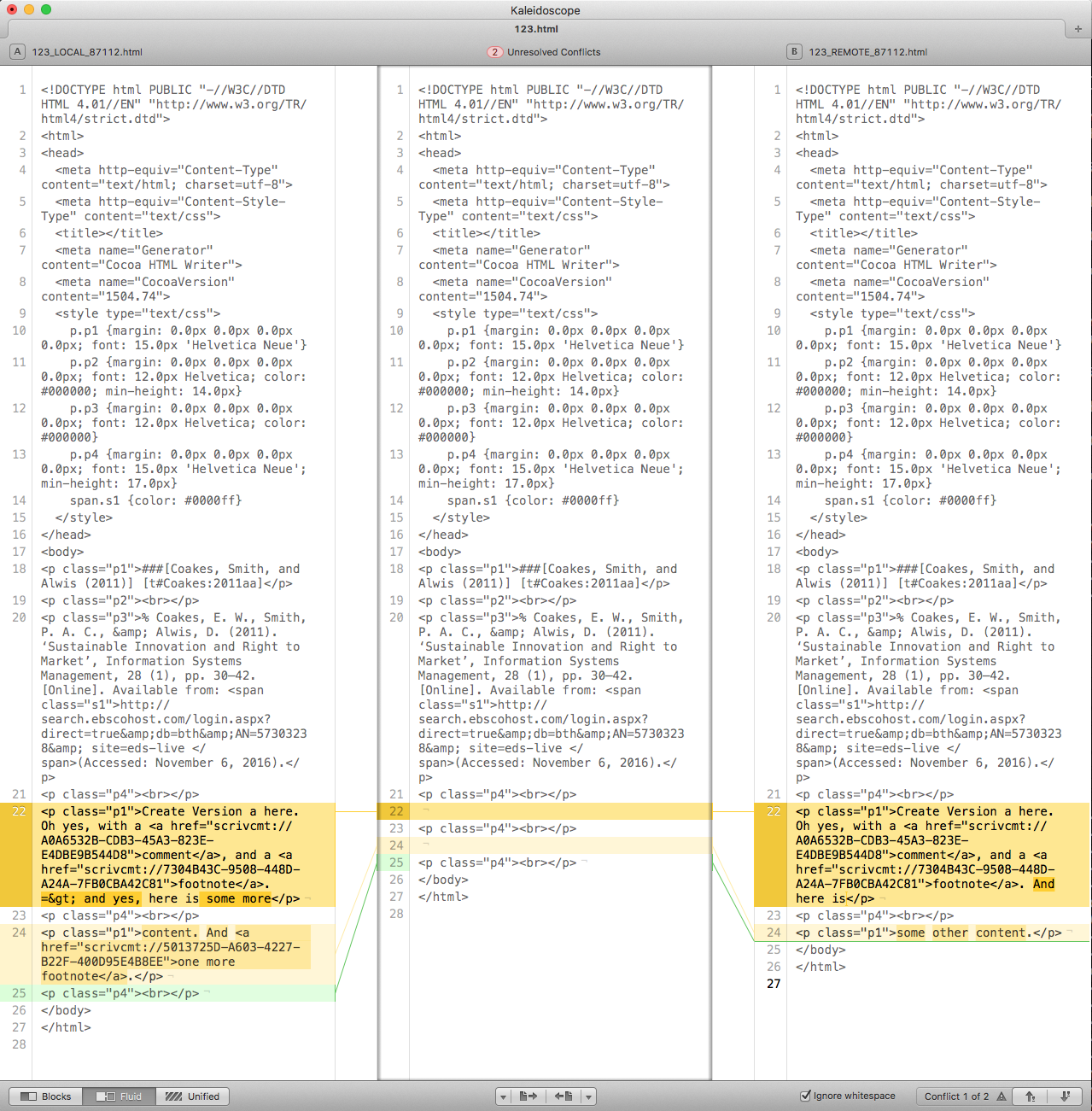
Kaleidoscope doesn’t work so well with HTML – how could it?
So while we can now formally merge, it really doesn’t help so much, as the real content is much harder to read, from Kaleidoscope or any other diff tool, compared to what we had before.
So what, do you think, could we do about this? We could of course solve this problem by yet another indirection, e.g., by stripping out all html content and marking up the remaining textual content with some IDs so that we would still remember, which bits of text we had were. For example, by wrapping every text into something like |id|text| and remembering some place, where that text lived in the HTML, we would have an option to be able to merge text, and then re-merge back in the html – and convert that back into rtf using Textutil. We’d still have to deal with images, which Textutil extracts into bmp files, but let’s assume we can somehow do that.
Conclusions
For me, while I really started to love Scrivener, this simple thing is something that makes me not like it – and yet I also must say, I don’t have so much of a better option really. At the end of the day, conceptually of course you end up getting dynamically named, e.g., numbered file names if you let the user shuffle them around. And why would you not allow for naming conflicts, because what you don’t want to do is to nag the user when he drags some content into some folder where there is already something by the same name. And why would you not use RTF, because after all, it allows the average user to do some formatting, and some images.
That leaves me with these options:
- I can well make use of Git. Git understands of course RTF, and
- Kaleidoscope will even nicely show the RTF in comparisons – we just won’t be able to merge there. We’d have to do it in Scrivener (and somehow as well, get around that while in a merge process, we’d be having files on the disks modified by Git which we are not able to make Scrivener work with).
- I can also extract the whole Scrivener content into a directory tree – even two ways.
- Scrivener is not able to version whole projects, it only does it on a per node level. We could potentially even hack this in by explicitly creating versions using a script – and Scrivener would pick them up.
This last point is something that is most interesting for me – at the end of the day, the whole thing is about versioning, which Scrivener does only half way – their programmers should really watch this video. They should really consider supporting a real versioning system from their point of view, which is simple right out of the box – and if they would do it, they could take care of the pre- and post processing and hence enable Git functionality on their rtf content.
What do you think?

Matthias, here is one more tip about Markdown in Scrivener that may or may not be useful for you, depending on how you organize your documents in Scrivener: It is not necessary to include headings with hashes (or number signs: ###) in your documents (as shown in your screenshot above). Instead, you can simply put the section heading in the title of each document (without hashes), and when you compile the project, you can adjust the settings in the structure and content table in the “Formatting” pane of the “Compile” window so that the proper quantity of number signs are prefixed to each document title in accord with its hierarchical level in the Binder. If you don’t want the titles of some documents included as headings, you can use a different section type for those documents. For my use, this is the only sane way to deal with Markdown headings in Scrivener. The beauty of Scrivener is that you don’t have to insert hashes manually at all; Scrivener will insert them for you at compile time (and of course Scrivener can do many other things automatically at compile time too, using, e.g., the “Replacements” pane of the “Compile” window).
That actually is an interesting point, as it would potentially allow me for more easy restructuring. Right now, when I move e.g. a subsection to become a section, I’ve to re-code the headers (remove one #). On the other hand, this would also logically then force me to have a substructure for each part. Maybe I’m going to make this optional. And then also, how would I encode the \section[TOC-Version]{Of some Section}.
I don’t use compile since it is too unreliable, too many clicks, and too slow.
Matthias, thanks for writing this; it is all very interesting, but I do not understand what your requirements are: Why do you need to use Git for version control of the .scriv file/directory? Have you considered other options, such as: (1) using Scrivener’s ability to sync with an external folder (File > Sync > Sync with External Folder…) and using Git for version control of the external folder, or (2) compiling to a composite Markdown file and using Git for version control of that file only? Scrivener was not designed for use with Git, but these are two other (perhaps better) ways to use Git with Scrivener.
If you are not familiar with Pandoc (http://pandoc.org), you could consider writing in Pandoc-flavored Markdown in Scrivener. Pandoc can convert to many other file formats, and Pandoc also supports delimited code blocks and code highlighting, if you include source code in your writing.
In case anyone else reads this, I will also mention that SourceTree is a free alternative to Tower as a graphical front end for Git, and TextWrangler/BBEdit can serve as a free alternative to Kaleidoscope for diffs (just select TextWrangler or BBEdit as your external diff tool in the SourceTree preferences).
Dear Nathan,
thanks a lot for your reply. For the deployment part, I’m working on a VM solution using Vagrant, so that’ll be upcoming relatively soon.
I don’t use Git for version control since Scrivener uses all RTF files which are not really nice to work with when it comes to diff.
I saw Pandoc, but I wanted to have more control over my parser. In any case, the parser is a configuration file already, so you can replace it with whatever you want.
Thanks for pointing out the free alternatives.
Matthias, I had forgotten about this post but then I happened to encounter it again, with your replies, via a Google search. In your reply, you said: “I don’t use Git for version control since Scrivener uses all RTF files which are not really nice to work with when it comes to diff.” Wait, WHAT? Then why did you a devote part of your post above to Git and “how can we make it work with Scrivener”? The fact that Scrivener uses RTF files internally is exactly why I asked whether you had considered the other two options: (1) using Scrivener’s ability to sync with an external folder (because the format of external synced files can be plain text, NOT RTF, which is perfect for people who write in Markdown or some other lightweight markup language in Scrivener), or (2) compiling to a composite Markdown file and using Git for version control of that file only. Obviously option 1 would be preferable in most cases, although option 2 might be preferred in some situations where the final product needs to be versioned but not the intermediate edits to the whole project. If neither of these options is viable for you that’s fine, of course, but I am glad that these options are mentioned here in the comments because option 1 is the easiest way to “version whole projects” with Git using plain-text files that are synced with Scrivener. And this way is built-in to Scrivener and does not require writing any special scripts.
Thanks Nathan. I’ve tried out your suggestion. Did you see that if you do so, and have a whole hierarchy of text assets in Scrivener that you synchronize with an external folder, you actually lose that hierarchy information?
So for example, I’m having Document A and Document B, one after the other. I synchronize and get 01 Document A (followed by a number which I assume is the ancient ID, but then it doesn’t have that information in the .scrivx), and 02 Document B. Now if I swap their order, they get renamed into 01 Document B and 02 Document A.
Which means, if I use Git to version that content, it doesn’t work: I’ll constantly lose assets in Git as they get renamed all the time.
For me, the main point for me to use Scrivener is to dynamically re-arrange documents / snippets as I am writing. It is a very convenient front-end to that. If I am using synchronization, I can’t see how I could benefit from Git: Yes, it does export, but no, I don’t maintain the asset order that I had before; it always exports everything, again, renumbering while doing so to maintain the order of the assets in the Scrivener hierarchy.
I don’t see really how Scrivener could do that differently; if it would at least maintain the link between the exported document and the Scrivener assets within the scrivx, one could work around that. But then I’d basically get what I already did.
Other problems I noticed while quickly trying: Scrivener adds line breaks to plain tex content that I have in the file. Which breaks, for example, LaTeX tables, as every single line breaks becomes a double line break, and hence a “no line to end here” error in LaTeX.
Scrivener also appears to only synchronize what’s in the drafts folder. Maybe I didn’t see that right. It does not allow to have media files there.
Then, it maintains a Trash folder in the synchronized folder which I don’t control the content of from the point of view of Scrivener.
So in summary, if at least it would keep a folder hierarchy, instead of having a flat list of files in the synchronized folder, it might be more useful, as it will be much easier to accept renamed files in some subfolders; still, the moment you rename a file, in Git you basically lose track of its version history.
So for the moment, the solution that I wrote seems much more convenient for me; or otherwise saying, I don’t see a way to use Git still.
Thanks for your comment!
Hi again. I can avoid having those line breaks added by asking Scrivener not to convert line breaks. At least that works. Now the problem remains with the document ordering. If Scrivener would at least maintain a folder hierarchy, instead of synchronizing everything into one folder, it might be an interesting avenue.
But then, what Scrivener does not to: “Include in compile.” It will export all documents, not just the ones that have been marked to be included in the compilation. I use that feature a lot to temporarily or definitely exclude a whole hierarchy of documents from being processed.
Matthias, thanks for the response. Yes, it’s true that syncing with an external folder in Scrivener does not preserve project hierarchy; its purpose is to duplicate the content of the documents in an external folder, not the project structure. If the numbers prefixed to filenames is a problem, the numbers can be turned off in the “Sync with External Folder” preferences window. It is true that filenames will change when document names change in the Scrivener project, but is it not the same as when filenames change in any other folder that is version controlled with Git?
Which option is best depends on the question of “requirements” that I mentioned in my original comment: “Why do you need to use Git for version control”? If one has certain requirements, it may be that Scrivener is not a good solution at all: for example, Scrivener would be an extremely bad choice for distributed, collaborative writing projects. And certainly one could never use Git with Scrivener in the same way that Git is used in software projects (if that is what you mean by “I don’t see a way to use Git”—i.e., I don’t see a way to use Git that is equivalent to the way that Git is used in software development—then I agree with you completely). But if one’s only requirement is, for example, a desire for an alternative way of viewing diffs between revisions of one’s Scrivener project, then one of the two options that I mentioned in my comment could prove satisfactory.
I write in Pandoc Markdown in Scrivener, and one way that I have versioned a Scrivener project is by using the “Back Up To…” and “Compile…” commands in tandem as follows: I have an external folder with a single backup of the Scrivener project and a single compiled Markdown file, and this folder is version controlled in Git. Each time I want to commit: first, I backup the Scrivener project to the folder, overwriting the previous backup; second, I compile to a compiled Markdown file in the folder, overwriting the previous compiled Markdown file; third, I commit the changes to the external folder with Git, writing a commit message. This allows me to view diffs in the compiled Markdown file, and I can roll back to a previous version of the Scrivener project if necessary. It is simple linear version control, but for the kind of work I do in Scrivener (i.e., given my “requirements”), that is all I need.
Hi Nathan,
thanks. Interesting what you say. Is not your compile -> git then a pretty much unidirectional thing? So what I’m doing a lot with git is to switch between versions / branches, and to recover work. If I imagine your process right, you couldn’t do that if you’d be compiling into one LaTeX file: Essentially, you’d have to look up from that file where some content came from in Scrivener, then go there and merge back manually the modification.
I am more and more visually using Scrivener as you can see from the ScreenShots I had posted in the Scrivener forums, such as this one:
https://i.imgur.com/SqUVh2X.png
Exporting using Pandoc I couldn’t really get patient enough to learn; I needed a very specific, small subset of commands, so I wrote TeXDown.
With that, I can easily add additional parsings as necessary. Within the upcoming months I’m planning to integrate better the handling of images (I want to basically copy/paste them into Scrivener, very similar to what I’m doing now with equations), and also add a snapshot feature to it. Snapshots in Scrivener are not bad, there are just too many of them, and I’d need a way to create manual snapshots hierarchically, just as I need to hierarchically exclude files from export. Also, I’m planning to do a demo installation in a VM using Vagrant.
Thanks again
Matthias, correct, my use of Git is almost entirely unidirectional; I use it as a record of the writing process. If I wanted to revert only a small section of text to a previous version, I would look at the diff of the compiled Markdown file, copy the section I wanted from the diff, and paste it manually into the working Scrivener project (which is possible because I write in Markdown, not rich text). I never create branches, and I don’t know why I would need branches as part of my writing process. I don’t have a software development background, so I think of the writing process as a series of drafts, not as a set of branches.
The reason why I write in Pandoc Markdown is because my destination format is usually not LaTeX; it is usually Adobe InDesign, and occasionally Microsoft Word. Pandoc allows me to write in Markdown and convert to those formats, or many other formats. Your requirements are clearly very different since know that your destination format is LaTeX.